I am co-organizing a special issue for the Computer Vision and Image Understanding journal on “Computer Vision and the Web”, together with Shih-Fu Chang (Columbia University), Gang Hua (Microsoft Research Asia), Thomas Mensink (Univ. of Amsterdam), Greg Mori (Simon Fraser Univ.) and Rahul Sukthankar (Google Research). You can see all the details on the call for papers.
I am co-organizing a special issue for the Computer Vision and Image Understanding journal on “Computer Vision and the Web”, together with Shih-Fu Chang (Columbia University), Gang Hua (Microsoft Research Asia), Thomas Mensink (Univ. of Amsterdam), Greg Mori (Simon Fraser Univ.) and Rahul Sukthankar (Google Research). You can see all the details on the call for papers.
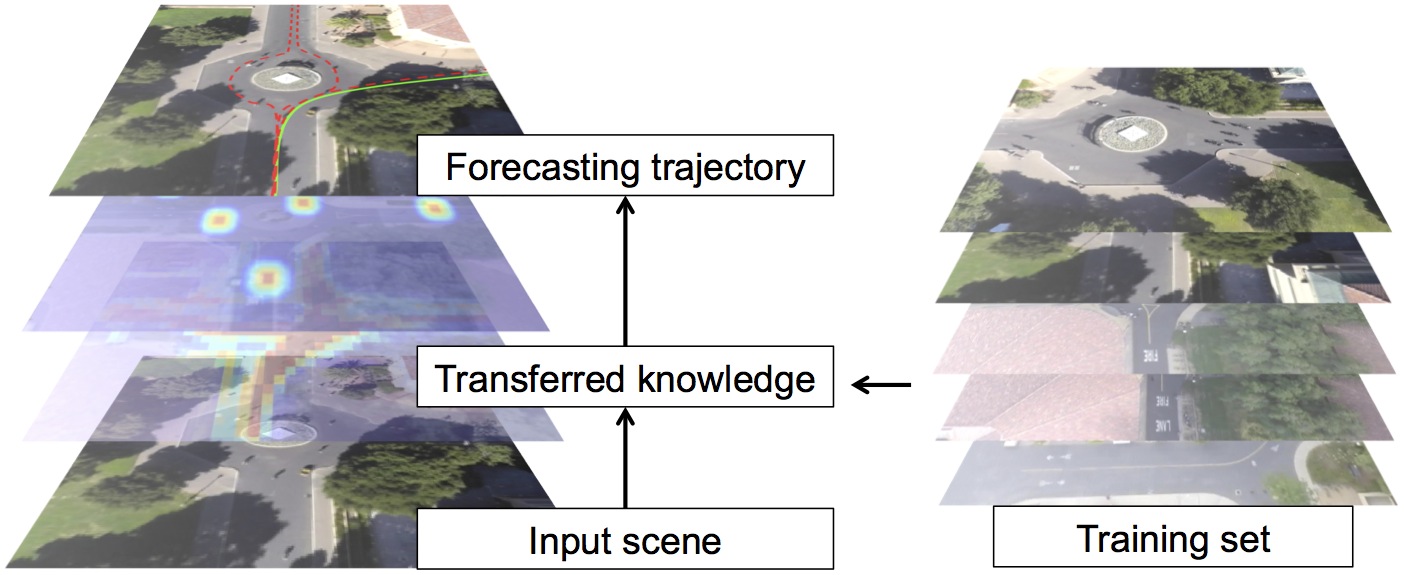
 Our paper “Knowledge Transfer for Scene-specific Motion Prediction”, by L. Ballan, F. Castaldo, A. Alahi, F. Palmieri and S. Savarese, has been accepted to ECCV 2016. A pre-print is available on arXiv.
Our paper “Knowledge Transfer for Scene-specific Motion Prediction”, by L. Ballan, F. Castaldo, A. Alahi, F. Palmieri and S. Savarese, has been accepted to ECCV 2016. A pre-print is available on arXiv.
When given a single frame of the video, humans can not only interpret the content of the scene, but also they are able to forecast the near future. This ability is mostly driven by their rich prior knowledge about the visual world, both in terms of (i) the dynamics of moving agents, as well as (ii) the semantic of the scene. We exploit the interplay between these two key elements to predict scene-specific motion patterns.
 In the past two weeks I have been involved as computer vision project mentor in the Stanford Artificial Intelligence Laboratory’s OutReach Summer program (SAILORS). SAILORS is a summer camp for high school girls and it is intended to increase diversity in the field of AI. SAILORS aims to teach technically rigorous AI concepts in the context of societal impact.
In the past two weeks I have been involved as computer vision project mentor in the Stanford Artificial Intelligence Laboratory’s OutReach Summer program (SAILORS). SAILORS is a summer camp for high school girls and it is intended to increase diversity in the field of AI. SAILORS aims to teach technically rigorous AI concepts in the context of societal impact.
Check out SAILORS blog to know more about the program. SAILORS was also recently featured in Wired.
I am co-organizing the 4th Int’l Workshop on Web-scale Vision and Social Media (VSM) at ECCV 2016, with Marco Bertini (Univ. Florence, Italy) and Thomas Mensink (Univ. Amsterdam, NL).
Website: https://sites.google.com/site/vsm2016eccv/
Vision and social media has recently become a very active inter-disciplinary research area, involving computer vision, multimedia, machine learning, and data mining. This workshop aims to bring together researchers in the related fields to promote new research directions for problems involving vision and social media, such as large-scale visual content analysis, search and mining.
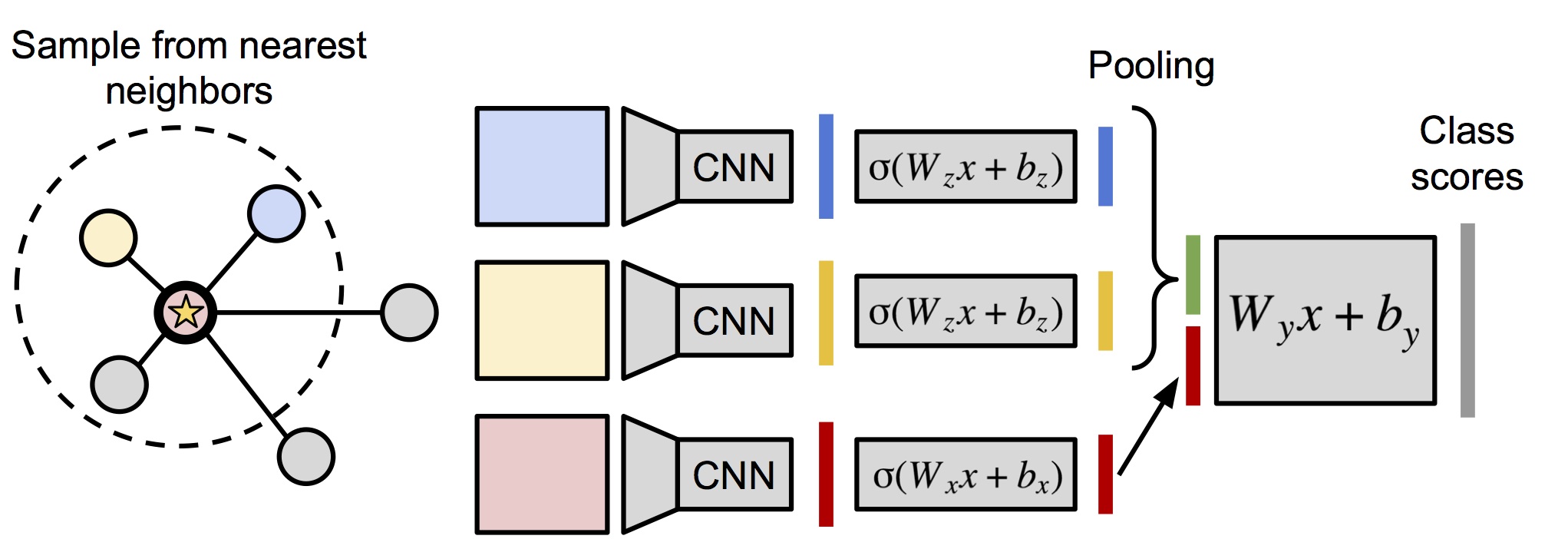
 Our paper “Love Thy Neighbors: Image Annotation by Exploiting Image Metadata”, by J. Johnson*, L. Ballan* and L. Fei-Fei (* equal contribution), has been accepted to ICCV 2015. A pre-print is now available on arXiv.
Our paper “Love Thy Neighbors: Image Annotation by Exploiting Image Metadata”, by J. Johnson*, L. Ballan* and L. Fei-Fei (* equal contribution), has been accepted to ICCV 2015. A pre-print is now available on arXiv.
Some images that are difficult to recognize on their own may become more clear in the context of a neighborhood of related images with similar social-network metadata. We build on this intuition to improve multilabel image annotation. Our model uses image metadata nonparametrically to generate neighborhoods of related images using Jaccard similarities, then uses a deep neural network to blend visual information from the image and its neighbors.
 I have just given a tutorial on kNN at the Stanford Artificial Intelligence Laboratory’s Outreach Summer program (SAILORS). SAILORS is designed to expose high school students in underrepresented populations to the field of Artificial Intelligence.
I have just given a tutorial on kNN at the Stanford Artificial Intelligence Laboratory’s Outreach Summer program (SAILORS). SAILORS is designed to expose high school students in underrepresented populations to the field of Artificial Intelligence.
The slides are available on this page and the Matlab code is also available for download. This is an updated version of the code used in class and should work also on Octave.
 Watch the TED 2015 talk by my postdoc advisor Prof. Fei-Fei Li about the recent advances in computer vision, from the detection and classification of objects in images to algorithms that are able to construct natural descriptions of those images. It is an exciting overview of the current state of the art in computer vision, in which she shares her thoughts on its potential use and impact. http://goo.gl/8O5Fch
Watch the TED 2015 talk by my postdoc advisor Prof. Fei-Fei Li about the recent advances in computer vision, from the detection and classification of objects in images to algorithms that are able to construct natural descriptions of those images. It is an exciting overview of the current state of the art in computer vision, in which she shares her thoughts on its potential use and impact. http://goo.gl/8O5Fch

Lorenzo Seidenari and I gave the tutorial “Hands on Advanced Bag-of-Words Models for Visual Recognition” at the ICPR 2014 conference (August 24, Stockholm, Sweden).
All materials – i.e. slides, Matlab code, images and features – and more details can still be found on this webpage.
University of Florence
Course on Multimedia Databases – 2013/14 (Prof. A. Del Bimbo)
Instructors: Lamberto Ballan and Lorenzo Seidenari

Goal
The goal of this laboratory is to get basic practical experience with image classification. We will implement a system based on bag-of-visual-words image representation and will apply it to the classification of four image classes: airplanes, cars, faces, and motorbikes.
We will follow the three steps:
- Load pre-computed image features, construct visual dictionary, quantize features
- Represent images by histograms of quantized features
- Classify images with Nearest Neighbor / SVM classifiers
Getting started
- Download excercises-description.pdf
- Download lab-bow.zip (type the password given in class to uncompress the file) including the Matlab code
- Download 4_ObjectCategories.zip including images and precomputed SIFT features; uncompress this file in lab-bow/img
- Download 15_ObjectCategories.zip including images and precomputed SIFT features; uncompress this file in lab-bow/img
- Start Matlab in the directory lab-bow/matlab and run exercises.m

MICC laboratories, Florence, 31th October 2013 (10.15-13.15). Course on Multimedia Databases (DBMM) – laboratory lecture.
- Goal: logo recognition in web images.
- Dataset/testset: find 4 different logos vs 110 images.
- Evaluation metrics: recognition performances will be evaluated in terms of mean Average Precision (mAP).
Instructors: Lamberto Ballan, Lorenzo Seidenari.
Download Software & Dataset  (* based on VLFeat library by A. Vedaldi)
(* based on VLFeat library by A. Vedaldi)
Final results (ranking): http://goo.gl/o5DCG5